When a model struggles, we ask it to think step by step. When a benchmark looks hard, we add reasoning traces. When a result improves, we treat the prompt as a recipe. In 2022, Jason Wei and colleagues showed that Chain-of-Thought (CoT) prompting could unlock complex reasoning in very large language models, with striking gains on arithmetic, commonsense, and symbolic tasks. On GSM8K, PaLM 540B with eight CoT exemplars reached state of the art performance and beat standard prompting by a wide margin.
The problem is not that this result was wrong. In my opinion, the problem is that the field turned a conditional result into a universal one. A method that worked for sufficiently large general models on certain reasoning benchmarks slowly became a default belief about how models should be used. Ask for more reasoning. Ask for more words. Ask for the hidden steps to become visible.
Now the conversation is changing again. A 2026 paper, Reasoning Models Struggle to Control their Chains of Thought, makes an important shift. It is not mainly about whether CoT improves task accuracy. It is about whether reasoning models can strategically shape what they reveal in those traces. The authors introduce the CoT-Control benchmark and show that current reasoning models are much better at controlling their final outputs than controlling their chain-of-thought. Claude Sonnet 4.5, for example, controls its chain-of-thought only 2.7% of the time, versus 61.9% for final outputs. The paper also finds that CoT controllability decreases with more Reinforcement Learning (RL) training, more test-time compute, and harder problems. (arXiv)
In one narrow sense, this is reassuring. If models still struggle to sanitize their visible reasoning, then CoT monitoring may remain useful as a safety signal. The paper itself ends on a cautious note of optimism about current monitorability, while warning that this capability could scale and should be tracked closely. A reasoning trace can be hard to fake and still be bad for the task. It can be monitorable and harmful at the same time. It can expose what the model is doing while also nudging the model into doing the wrong thing. That distinction matters a lot, especially in medicine.
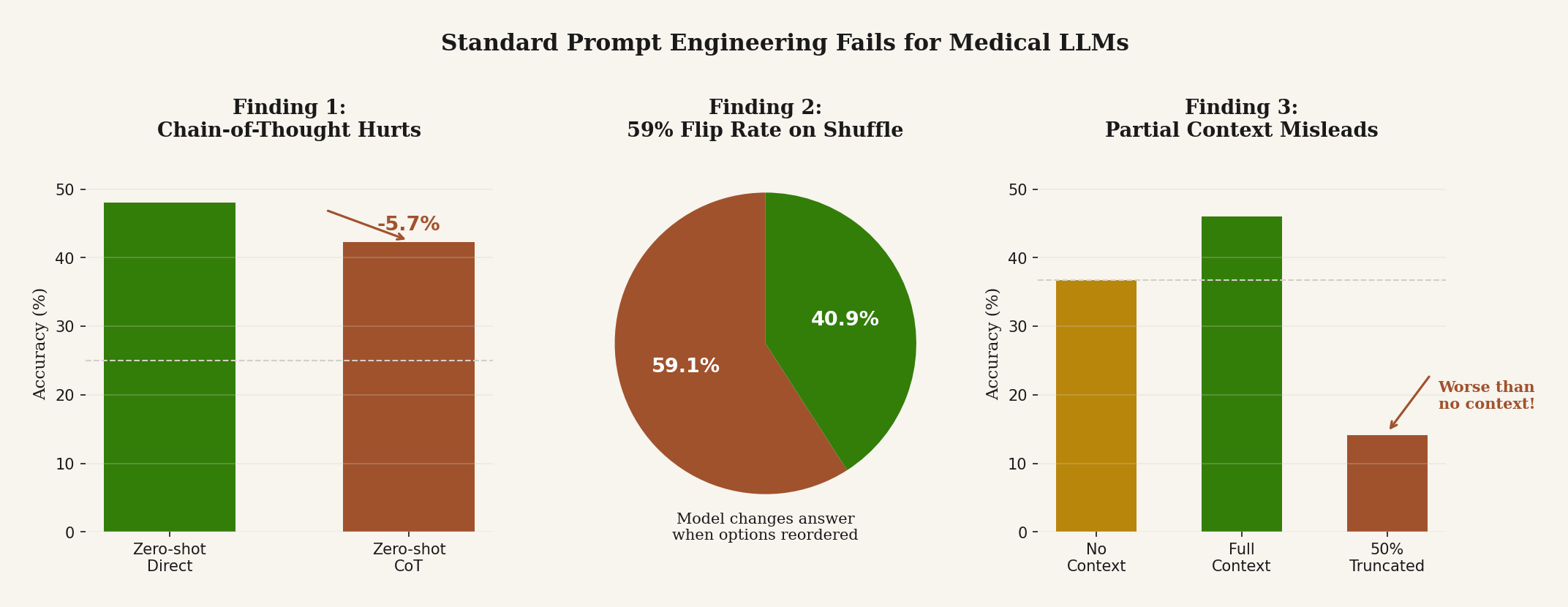
That is exactly what I found in our paper on prompt sensitivity in medical language models. We evaluated MedGemma 4B and 27B on 4,183 MedMCQA questions and 1,000 PubMedQA examples. Zero-shot direct prompting performed best. Chain-of-thought reduced accuracy by 5.7 percentage points. Few-shot examples were even worse, reducing accuracy by 11.9 points while pushing position bias from 0.137 to 0.472. The usual “best practices” did not help. They actively hurt.
And the failure was not random noise. When chain-of-thought changed the answer, it hurt more often than it helped. It flipped 1,262 predictions, with 750 harmed cases versus 512 helped. The pattern was ugly and familiar: long reasoning, self-contradiction, and a model that seemed to talk itself out of the correct answer. In other words, the visible reasoning was not a clean window into competence. Often it was the mechanism of failure.
The multiple-choice results were worse. When we shuffled answer options, MedGemma changed its answer 59.1% of the time. Simple rotations dropped accuracy by as much as 27.4 points. That means the model was often reacting to position, not content. A system that changes its medical answer because the choices were rearranged is not reasoning in any meaningful sense that should comfort us. It is pattern matching with a lab coat on.
Partial context was worse than no context. On PubMedQA, truncating context to 50% dropped MedGemma-4B to 14.1% accuracy, far below its 36.7% question-only baseline. Meanwhile, results-only context came close to full context for 4B and actually beat full context for 27B. That matters for medical Retrieval-Augmented Generation (RAG) systems because it means retrieval is not a free upgrade. Incomplete evidence can actively mislead the model. More text is not always more truth. Sometimes it is just more surface area for confusion.
In a December 2025 paper, Leviathan, Kalman, and Matias at Google Research showed that simply repeating the input prompt, duplicating it so every token can attend to every other token, outperformed baselines in 47 of 70 benchmark-model tests with zero losses. On some tasks the gains were dramatic: Gemini 2.0 Flash-Lite jumped from 21.3% to 97.3% accuracy on a name-indexing task. This technique adds no generation tokens at all. It only extends the prefill, so there is no latency cost. And when the authors tested it alongside reasoning models, the effect was neutral, because reasoning models already repeat parts of the prompt internally during inference. (arXiv)
If a mechanical trick like saying the same thing twice can match or beat “think step by step” on dozens of benchmarks, then maybe what CoT is doing in some cases is not reasoning at all. Maybe it is just giving the model more tokens to attend over. More attention surface, not more thought.
A 2026 ICLR workshop paper by Frey et al., Adaptive Loops and Memory in Transformers, pushes this further. They show that transformers equipped with per-layer adaptive loops, where blocks learn when to iterate via a halting mechanism, can improve mathematical reasoning without any visible chain-of-thought at all. The model refines its representations internally, inside hidden states, rather than spelling out intermediate steps in text. Looping helped math; separate gated memory banks helped commonsense tasks. The combined approach outperformed baselines while staying parameter-efficient. (arXiv)
That matters because it separates the question of whether a model reasons from the question of whether it reasons out loud. If internal loops can match or exceed explicit CoT on math tasks, then visible reasoning is not the only path to better answers. It may not even be the best one. And it raises an uncomfortable possibility for safety: the models we can monitor through their chains of thought may not be the ones that reason most effectively.
Put these five papers together and a more honest picture appears. The 2022 paper showed that chain-of-thought can unlock capability in very large general models. The 2026 controllability paper suggests that CoT may still be useful for monitoring because current models struggle to fully sanitize it. The prompt repetition paper hints that some of CoT’s gains may come from attention mechanics rather than genuine reasoning. The adaptive loops paper shows that models can reason internally without producing any visible trace at all. And our paper shows that in medical question answering, asking for chain-of-thought can make the model less accurate, less stable, and more biased. Same interface. Five very different stories.
What bothers me is not that the literature is mixed. Mixed results are normal. “Use chain-of-thought.” “Use few-shot.” “Use more context.” These are not laws of nature. They are interventions. And in high-stakes domains, interventions should be treated with suspicion until they survive contact with reality.
Healthcare is where this matters most. A benchmark score can hype a model and over sell it, I have been hearing from seasoned professionals that radiologists are needed no more . A polished rationale can flatter a reader. But a system that flips when options are reordered, degrades when reasoning is elicited, and collapses under partial evidence is not strong enough to earn trust just because it sounds thoughtful. In a clinical setting, sounding thoughtful is cheap. Staying correct under perturbation is expensive.
So I think the field needs to grow out of its fascination with visible reasoning as a universal sign of progress. The better question is no longer whether a model can think out loud. The better question is what happens when we make it do so. Does accuracy improve or fall? Does bias shrink or grow? Does the reasoning help oversight, or does it create a new failure mode? Does retrieval ground the answer, or poison it with fragments?
I am not saying Chain-of-thought is not dead. It is a capability scaffold in one setting, a monitoring surface in another, and a source of brittleness in a third. We should stop treating prompt engineering as folklore and start treating it as an empirical object. Especially in medicine, where a model does not get credit for sounding smart. It gets judged, eventually, on whether it stays right when the prompt, the context, and the world stop being neat.