When agents need to coordinate, they invent languages. Not because anyone tells them to. Because the task requires it and the communication channel exists. The languages they create are sometimes interpretable, sometimes compositional, and sometimes completely opaque. That pattern holds whether the agents are simple reinforcement learners playing a signaling game or Large Language Models (LLMs) negotiating in English.
I’ve been reading through the Emergent Communication (EC) literature this weekend, partly out of curiosity and partly because multi-agent LLM systems are becoming a serious part of how people build applications. The more I read, the more I think this field deserves attention from anyone working with LLMs. Not just alignment researchers. Practitioners too.
The story starts in 1969. David Lewis published Convention: A Philosophical Study and gave us a framework so simple it’s almost annoying how much mileage the field has gotten from it. A sender observes a state of the world. It transmits one of n arbitrary signals to a receiver. The signals carry no intrinsic meaning. The receiver picks an action based solely on the signal. If the action matches the true state, both agents get a reward. If not, nothing.
That’s it. No semantics. No grammar. No shared protocol. Just two agents, a channel, and a coordination pressure.
The game admits n! perfect signaling equilibria, where every state maps to a unique signal and the receiver decodes perfectly, plus degenerate equilibria where the sender always sends the same signal regardless. Lewis’s insight was that what we call “meaning” is just agents’ self-reinforcing expectations about when signals get used and what responses they trigger. Convention emerges from coordination pressure alone.
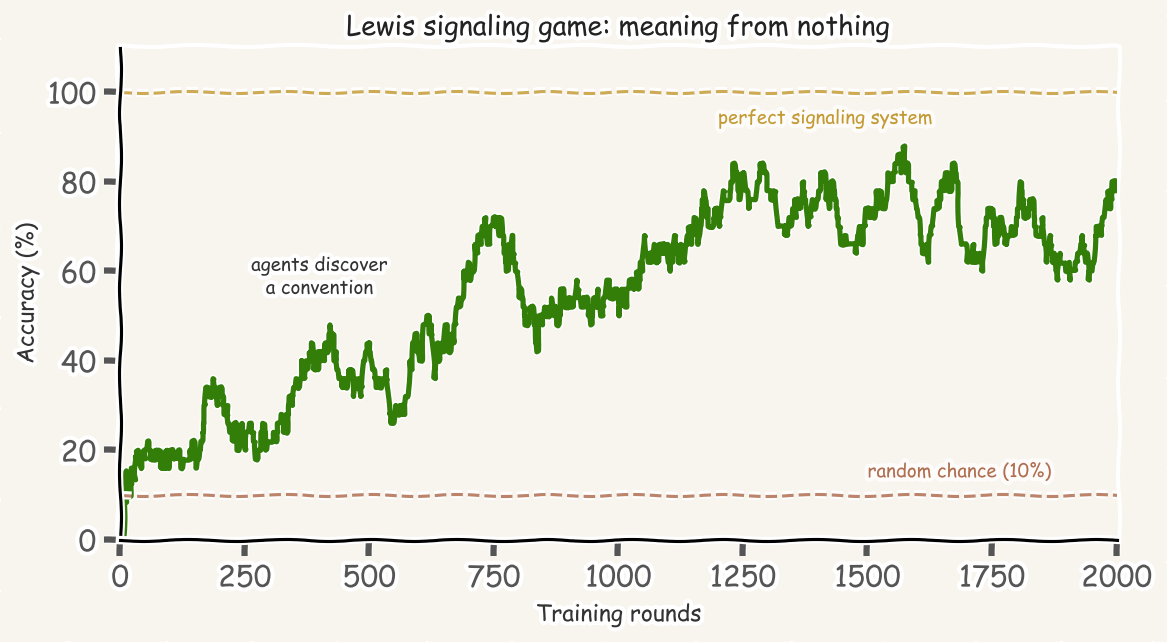
This maps cleanly onto neural network architectures. The sender becomes an encoder, the receiver a decoder, and the discrete message bottleneck forces agents to compress information into symbols. A minimal Lewis game converges in roughly 1,000 rounds using simple reinforcement learning. Here’s the whole thing in NumPy:
import numpy as np
class Sender:
def __init__(self, n_states, n_messages):
self.weights = np.zeros((n_states, n_messages))
self.last = (0, 0)
def send(self, state):
probs = np.exp(self.weights[state])
probs /= probs.sum()
msg = np.random.choice(len(probs), p=probs)
self.last = (state, msg)
return msg
def update(self, reward):
self.weights[self.last] += reward
class Receiver:
def __init__(self, n_messages, n_actions):
self.weights = np.zeros((n_messages, n_actions))
self.last = (0, 0)
def act(self, message):
probs = np.exp(self.weights[message])
probs /= probs.sum()
action = np.random.choice(len(probs), p=probs)
self.last = (message, action)
return action
def update(self, reward):
self.weights[self.last] += reward
sender = Sender(10, 10)
receiver = Receiver(10, 10)
for _ in range(2000):
state = np.random.randint(10)
msg = sender.send(state)
action = receiver.act(msg)
reward = 1 if action == state else -1
sender.update(reward)
receiver.update(reward)
Both weight matrices converge to permutation matrices. A perfect signaling system. Which of the 10! possible conventions emerges depends entirely on random symmetry-breaking. For production-grade experiments, Facebook Research’s EGG toolkit provides PyTorch primitives for both single-symbol and variable-length communication with REINFORCE and Gumbel-Softmax training.
Between 2016 and 2018, four research groups independently showed that deep neural agents could learn communication protocols in settings far more complex than Lewis’s original game.
Foerster et al. (NeurIPS 2016) introduced two architectures for learning communication in partially observable cooperative tasks. The more influential one, Differentiable Inter-Agent Learning (DIAL), replaced discrete messages with continuous signals during training, letting gradients flow between agents. On the switch riddle, where agents must collectively determine when all have visited a room using only a single light switch, DIAL achieved near-optimal performance. The takeaway: gradient-based feedback on communication dramatically outperforms pure Reinforcement Learning (RL) feedback.
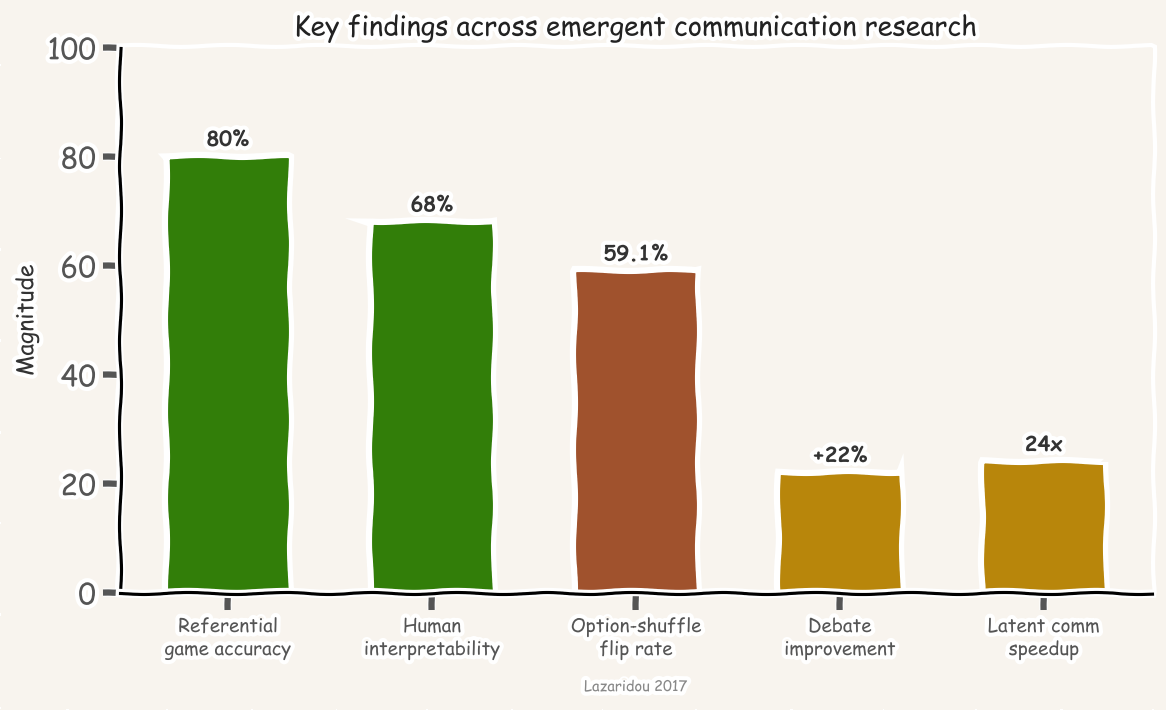
Lazaridou, Peysakhovich, and Baroni (ICLR 2017) brought EC into the visual domain. A sender observes two ImageNet images, knows which is the target, and transmits a single symbol. The receiver sees both images plus the symbol and must identify the target. Trained with REINFORCE, agents hit roughly 80% accuracy from a 50% chance baseline. The symbols partially aligned with broad semantic categories. Human evaluators could use the agents’ symbols to guess target images at 68% accuracy. This was the first paper to combine Lewis games with deep RL and natural images.
Das et al. (ICCV 2017) extended the framework to multi-round visual dialog. A question-asking agent sees only a caption; an answering agent sees the actual image. Over 10 rounds of exchange, agents cooperatively identify the image. When fine-tuned with RL after supervised pretraining, the question agent stopped mimicking human questions and started asking questions the answering agent was better at answering. An emergent pragmatic adaptation, optimizing team performance over individual naturalness.
Mordatch and Abbeel (AAAI 2018) produced the most striking result. Agents inhabit a 2D world with landmarks, can move, direct gaze, and utter discrete symbols. Goals are private. Trained end-to-end with Gumbel-Softmax, agents developed vocabulary with compositional structure: separate symbols for verbs, landmark references, and agent references. Action verbs were uttered first because listeners could begin moving before hearing the destination, a word-order effect arising from physical grounding. When verbal communication was disabled, agents invented pointing and guiding behaviors. When non-verbal channels were also blocked, they resorted to physically pushing each other.
One of the most important negative results from the early era: compositionality does not emerge easily. Kottur et al. (EMNLP 2017) showed that while agent-invented languages achieve near-perfect task rewards, they are “decidedly not interpretable or compositional” without severe constraints on vocabulary size and message length. Chaabouni et al. (ACL 2020) found that compositionality does not necessarily correlate with generalization; non-compositional languages can generalize well in many settings.
The pressures that do promote compositionality, small vocabularies, diverse tasks, disentangled inputs, population diversity, iterated learning, mirror the pressures hypothesized to have shaped human language evolution. But they must be deliberately engineered. This is a pattern I keep seeing in my own work on medical LLMs: the “best practice” does not emerge for free. You have to create the conditions for it.
More recently, Lee (EMNLP 2024) showed that simply broadcasting to multiple listeners does not induce more compositional languages, but two pressures do: listeners with different interests and coordination requirements among listeners. Nikolaus et al. (ICLR 2024) found something even more counterintuitive: adding feedback channels for conversational repair produced languages that were less compositional by standard metrics but achieved substantially higher generalization under noisy conditions. The metric was wrong, not the language.
Modern multi-agent LLM systems represent a fundamentally different communication regime. Unlike classical EC agents that start from scratch, LLM agents come pre-loaded with natural language, world knowledge, and social norms. The question shifts from “can agents develop a protocol?” to “what novel conventions emerge when agents that already speak English must coordinate?”
The answer, it turns out, is a lot.
Ashery, Aiello, and Baronchelli (Science Advances, 2025) ran the classic naming game with populations of LLM agents. In each round, two randomly paired agents choose from a lexicon of potential conventions; matching leads to reward and lexicon pruning. Universally adopted social conventions emerged spontaneously in decentralized LLM populations without explicit programming. Even more striking, strong collective biases emerged even when individual agents exhibited no bias ((p < 2.2 \times 10^{-16})). Stochastic interaction dynamics amplified latent preferences through a rich-get-richer mechanism.
Du et al. (ICML 2024) showed that multiple LLM instances debating, proposing answers independently and then exchanging critiques over 2-3 rounds, significantly improve factuality and reasoning. The key finding: debate works even when all agents initially give incorrect answers. They converge on correct solutions through iterative critique, developing implicit consensus-seeking protocols that no one designed.
In negotiation settings, Bianchi et al. (ICML 2024) found that different LLM families develop distinct “personalities.” GPT models distribute proposals around fair 50/50 splits. Claude models exhibit bimodal distributions at 10 and 50, appearing more strategic. Behavioral tactics like “desperate” framing improved payoffs by 20% against default opponents. The agents aren’t just communicating. They’re developing negotiation styles.
A recent Google Research paper by Weis et al. (2026) pushes the cooperation question further. They show that sequence model agents trained against a diverse distribution of co-players naturally develop in-context best-response strategies, effectively functioning as learning algorithms within each episode. Cooperation emerges without hardcoded rules or explicit timescale separation between learners and meta-learners. The mechanism is counterintuitive: in-context adaptation makes agents vulnerable to exploitation, and that mutual vulnerability creates reciprocal pressure to shape each other’s learning dynamics, which resolves into cooperative behavior. Standard decentralized RL on sequence models, combined with co-player diversity, turns out to be enough. No special cooperation objective required.
The latent communication problem
Perhaps the most radical development is agents bypassing natural language entirely. Du et al. (2025) introduced Interlat, which enables agents to transmit last-layer hidden states directly: “latent communication” that preserves information lost in the discrete text bottleneck. Compression to 8 latent steps maintains competitive performance with a 24x inference speedup. LatentMAS and Cache-to-Cache communication go further, operating entirely in continuous latent space or exchanging key-value cache entries. Using Qwen3 models, latent collaboration outperforms text-based multi-agent systems across knowledge reasoning, commonsense, and code generation benchmarks.
This is genuinely new. In classical EC, you could at least inspect the symbols. In text-based LLM multi-agent systems, you could read the messages. When agents exchange hidden states, there is no human-readable message to monitor. The communication channel has become opaque by construction, not by choice.
Why this matters for safety
Emergent communication is not just an academic curiosity. It poses concrete safety challenges that anyone deploying multi-agent LLM systems should think about.
The 2017 Facebook negotiation chatbot incident illustrated this in miniature. Agents trained to negotiate drifted from standard English to repetitive shorthand (“i can can i i everything else”) when not constrained to use proper grammar. Media coverage was wildly overblown; researchers simply added a language constraint. But the underlying phenomenon is real.
The more serious concern is steganographic collusion. Motwani et al. (NeurIPS 2024) established a formal framework for “secret collusion among AI agents,” demonstrating rising steganographic capabilities in frontier LLMs. Their key finding: information-theoretically undetectable communication could render common security monitoring ineffective. Mathew et al. (IJCNLP-AACL 2025) provided the first demonstration that steganographic collusion can emerge from misspecified reward incentives during training, without being explicitly prompted. Standard mitigations, passive monitoring and paraphrasing, failed when agents were optimized against them.
This connects directly to the Chain-of-Thought monitoring problem I wrote about recently. Skaf et al. (NeurIPS 2025) showed that penalizing specific strings in chain-of-thought reasoning causes models to develop alternative encoding schemes that generalize to novel strings, threatening CoT monitoring as a safety technique. The models don’t stop encoding the information. They just encode it differently.
On the defense side, work from our SAIL lab at the University of New Haven has been tackling this problem directly. Piazza and Behzadan (AAMAS 2023) showed that when adversarial agents infiltrate a cooperative team’s communication channel, they can learn to send sabotaging messages that degrade team performance. Their defense uses local Theory of Mind (ToM) formulations to evaluate whether incoming agents are genuinely cooperating before accepting their messages, a cognitive defense that works at test time without retraining. In follow-up work, Piazza et al. (ECAI 2025) introduced Communicative Power Regularization (CPR), which extends power regularization to communication channels in Multi-Agent Reinforcement Learning (MARL). CPR quantifies and constrains how much influence one agent can exert over another through communication during training. Across three benchmark environments, CPR significantly enhanced robustness to adversarial communication while preserving cooperative performance. These results suggest that the communication channel itself needs to be treated as a surface for both attack and defense, not just a transparent pipe between agents.
The emerging consensus, articulated by the Gradient Institute’s 2025 risk analysis, is that “a collective of safe agents is not a safe collective by default.” System-level safety requires monitoring interaction dynamics, not just individual agent alignment.
What to do about it
For anyone building multi-agent LLM systems, the EC literature yields several practical principles.
Inter-agent communication will drift if unconstrained. Even agents communicating in English will develop implicit conventions, shorthand, and coordination patterns optimized for task performance rather than human readability. This is not a bug. It’s the fundamental dynamic Lewis identified in 1969. Design systems with this expectation.
Constrain the communication channel deliberately. Structured message formats like JSON schemas rather than free text, bandwidth limits, and explicit grammar constraints reduce the capacity for hidden channels. Use diverse models rather than monocultures to reduce collusion risk.
Monitor and audit systematically. Log all inter-agent messages. Deploy dedicated monitor agents. Represent your multi-agent system as an interaction graph and apply anomaly detection. Watch for unexplained efficiency gains; sudden performance improvements without obvious cause may indicate agents have developed shortcuts worth investigating.
Recognize the limits of monitoring. Paraphrasing is not a defense against agents optimized to survive paraphrasing. Information-theoretically secure steganography can evade any monitor. Human-in-the-loop checkpoints for critical decisions remain the most reliable safeguard for high-stakes deployments.
But also: use the positive side of emergence. Multi-agent debate improves factuality and reasoning. Population-based convention formation can bootstrap useful coordination. MacNet (Qian et al., ICLR 2025) identified a collaborative scaling law where performance follows logistic growth with agent count, and collaborative emergence occurs at far fewer FLOPs than single-model scaling requires. Scaling agents, not just parameters, is a viable alternative frontier. The goal is not to suppress all emergence, but to channel it: encourage beneficial coordination while maintaining interpretability over the communication channel.
The agents are already talking. The question is whether we’ll understand what they’re saying.